Comprehensions
A comprehension builds one sequence from another in a single expression. The idea comes from functional programming, and before that from the set-builder notation of mathematics. Haskell had list comprehensions, and Python borrowed them.
Comprehensions take a mind shift. With a loop you describe how to build the result: make an empty list, walk the input, test each item, and append the ones you want. With a comprehension you describe what the result is, as a single expression, and let Python build it. A comprehension is shorter, it reads like the definition of the result rather than a recipe for it, and one line replaces several lines of loop bookkeeping.
List Comprehensions
A list comprehension consists of the following parts:
- An Input Sequence.
- A Variable representing members of the input sequence.
- An Optional Predicate expression.
- An Output Expression producing elements of the output list from members of the Input Sequence that satisfy the predicate.
Say we need to obtain a list of all the integers in a sequence and then square them:
# list_comprehension.py
a_list = [1, "4", 9, "a", 0, 4]
squared_ints = [e ** 2 for e in a_list if isinstance(e, int)]
print(squared_ints)
# [1, 81, 0, 16]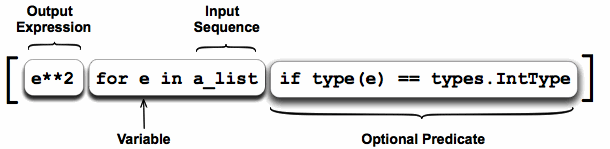
The comprehension has three parts:
- The iterator part iterates through each member
eof the input sequencea_list. - The predicate checks if the member is an integer.
- If the member is an integer then it is passed to the output expression, squared, to become a member of the output list.
Much the same results can be achieved using the built-in
functions, map, filter and the anonymous
lambda function.
The filter function applies a predicate to a sequence:
filter(lambda e: isinstance(e, int), a_list)map modifies each member of a sequence:
map(lambda e: e ** 2, a_list)The two can be combined:
map(lambda e: e ** 2, filter(lambda e: isinstance(e, int), a_list))The above example involves function calls to map,
filter, isinstance and two calls to
lambda. Function calls in Python are expensive.
Furthermore the input sequence is traversed through twice and an
intermediate list is produced by filter.
The list comprehension is enclosed within a list, so it is
immediately evident that a list is being produced. There is only one
function call to isinstance and no call to the cryptic
lambda; instead the list comprehension uses a
conventional iterator, an expression and an if
expression for the optional predicate.
Nested Comprehensions
An identity matrix of size n is an n by n square matrix with ones on the main diagonal and zeros elsewhere. A 3 by 3 identity matrix is:
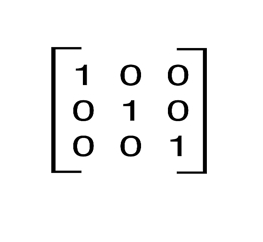
In Python we can represent such a matrix by a list of lists, where each sub-list represents a row. A 3 by 3 matrix is represented by the following list:
[ [ 1, 0, 0 ],
[ 0, 1, 0 ],
[ 0, 0, 1 ] ]The above matrix can be generated by the following comprehension:
[[1 if col == row else 0 for col in range(3)]
for row in range(3)]Techniques
Using zip() and dealing with two or more elements at
a time:
['%s=%s' % (n, v) for n, v in zip(self.all_names, self)]Multiple types (auto unpacking of a tuple):
[f(v) for (n, f), v in zip(cls.all_slots, values)]A two-level list comprehension using
Path.walk():
# os_walk_comprehension.py
from pathlib import Path
rst_files = [
dirpath / f
for dirpath, _, files in Path(".").walk()
for f in files if f.endswith(".rst")
]
for r in rst_files:
print(r)Set Comprehensions
Set comprehensions allow sets to be constructed using the same principles as list comprehensions. The only difference is that the resulting sequence is a set.
Say we have a list of names. The list can contain names which only differ in the case used to represent them, duplicates and names consisting of only one character. We are only interested in names longer than one character and wish to represent all names in the same format: The first letter should be capitalized; all other characters should be lower case.
Given the list:
names = [ 'Bob', 'JOHN', 'alice', 'bob', 'ALICE', 'J', 'Bob' ]We require the set:
{ 'Bob', 'John', 'Alice' }The following set comprehension accomplishes this:
{name[0].upper() + name[1:].lower()
for name in names if len(name) > 1}You could get the same result by passing a list comprehension to
set(). That builds a throwaway list first, so the set
comprehension is the better choice:
set([name[0].upper() + name[1:].lower()
for name in names if len(name) > 1])Dictionary Comprehensions
Say we have a dictionary the keys of which are characters and the values of which map to the number of times that character appears in some text. The dictionary currently distinguishes between upper and lower case characters.
The following is inefficient: If both a lower case and upper case character exists, then the entry in the new dictionary is updated twice.
We require a dictionary in which the occurrences of upper and lower case characters are combined:
mcase = {'a':10, 'b': 34, 'A': 7, 'Z':3}
mcase_frequency = {
k.lower(): mcase.get(k.lower(), 0) + mcase.get(k.upper(), 0)
for k in mcase
}# mcase_frequency == {'a': 17, 'z': 3, 'b': 34}A comprehension is evaluated eagerly. It builds the whole result in memory before the next statement runs. For a large input that wastes time and space, especially when you consume the result only once. A generator expression uses the same syntax with parentheses instead of brackets, and produces its values one at a time, on demand:
squares = (n ** 2 for n in range(1_000_000))Nothing is computed until you iterate over squares,
and only one value exists at a time. The Iterators chapter covers generators in
depth.
Portions of this chapter were contributed by Michael Charlton.